Semantic analysis of GOP debates
A few weeks ago, I played around with extracting key phrases from GOP debates using statistical measures to identify groups of words spoken by candidates. Some of the phrases were pretty good, but they were missing a clear topical direction; a pure lexical approach fails to exploit similarities between phrases such as "islamic_extremism" and "islamic_radicals," among other deficiencies.
This time, I pushed the GOP debate transcripts through Mallet, a popular implementation of LDA topic modeling written in Java by Andrew McCallum at the University of Massachusetts. made available under the Common Public License.
I still had lists of "key phrases" from the last GOP analysis I did, so with a simple search and replace, I was able to turn multi-word phrases into single words by replacing spaces with underscores; that is, "islamic terror" becomes the single word "islamic_terror" -- prior to vectorizing and training the topic model. This ensured that key words don't get split apart by the model.
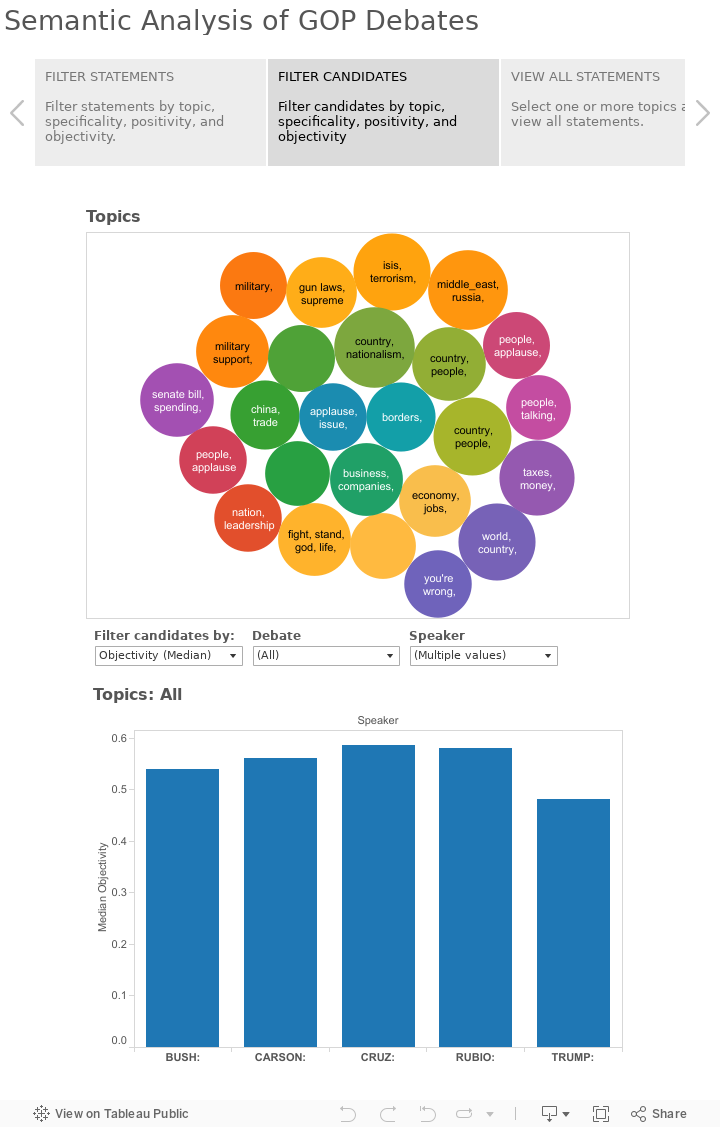
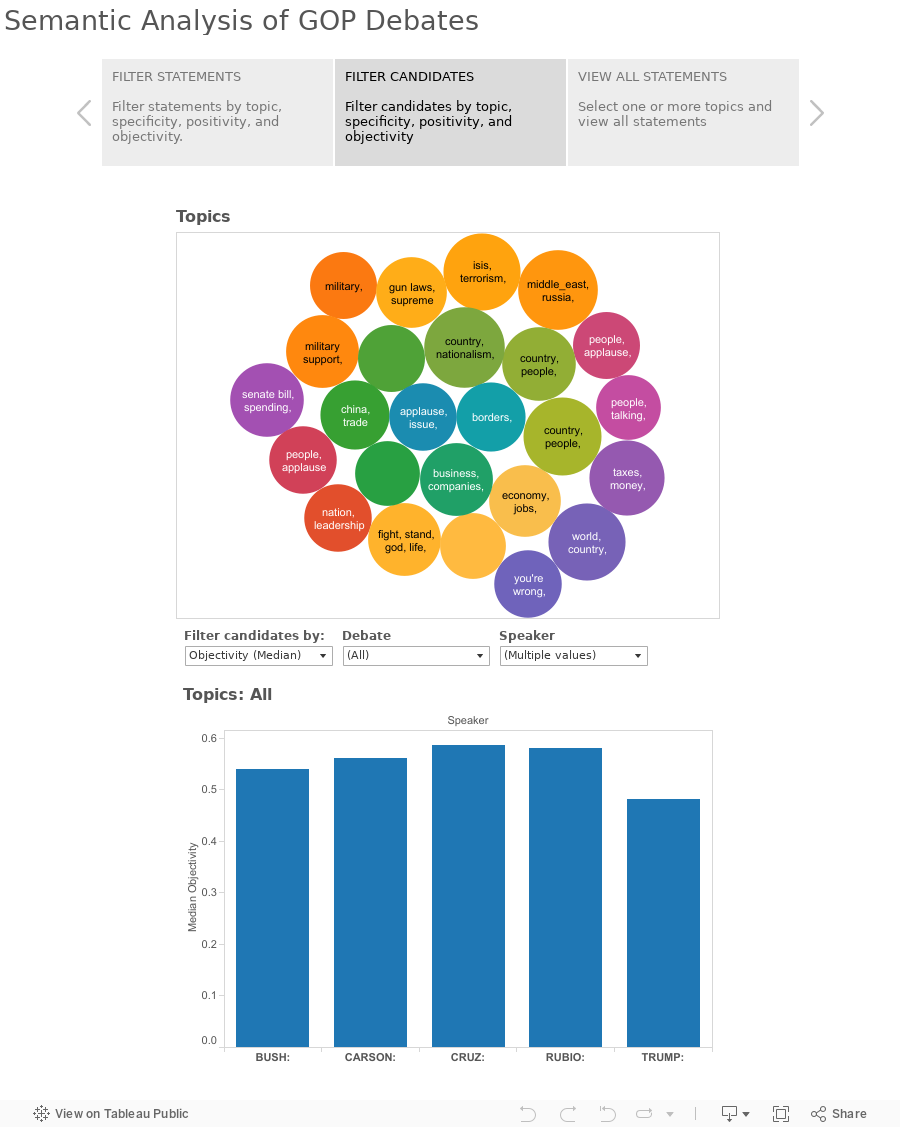
I eyeballed the topic model results and settled on a 20-topic model; I didn't perform any sophisticated quantitative measurements -- with such a small corpus, it was fairly easy to judge topic cohesion across the topic words at the end of each sampling and adjust accordingly.
After training a topic model across 20 possible topics, I was able to assign topic proportions across all candidate statements; for example, Trump speaks more about "winning elections, campaigning, Hilary Clinton" than any other topic whereas Bush talks most about "country, people, family" and Cruz's largest topic is "borders, immigration, people."
Using off-the-shelf lexicons of subjective adjectives and moderators, as well as open-source research packages from the Computational Linguistics and Psycholinguistics Research Center, I took the additional step of parsing statements by parts of speech and calculating subjectivity, positivity, and specificity as a pure heuristic based on the presence of pre-tagged lexical terms.
Objectivity
Objectivity is measured as a proportion of parts of speech that contain subjective or objective mood, plotted between 0.0 and 1.0. An example of an objective statement is, "I'm going to talk about my record" (1.0) and a subjective statement is "I think it's great that businesses start a 401k." (0.0) -- you can play with these values to select the most (or least) objective statements made by a candidate on any topic. (Both of those are actual statements from the debates, btw)
Positivity
This is measured by searching for the presence of certain key words from a lexicon (i.e. good or bad) with polarity values between -1.0 (negative) and 1.0 (positive). This should be somewhat self-evident. Note that lexical polarity is not necessarily a measurement of quality: "I hate cancer" is a lexically negative statement, but with positive semantic overtones which are lost in these kind of simple analyses. That's another fun problem for another day.
Specificity
Measured as a value between -1.0 (non-specific) and 1.0 (specific), the specificity of a statement depends on the grammatical mood of auxiliary verbs and adverbs which imply certainty or ambiguity (i.e. definitely, maybe, or the use of subjunctive verbs such as "wish")
Up next
I think next I'm going to run a similar analysis on the Democratic debates. Hopefully, we'll soon have primary election results and perhaps we can correlate some of the debate features to election results. Also, I had a good time playing with modality/subjectivity scores so I think I'm going to dive into that a bit.
As always, I'll put the code for this up onto github as soon as I get it cleaned up enough to have company. Feel free to follow that repo so you can get updated when I finally push.